摘要
几乎所有基于优化的VIO系统,都会提到利用 Marginalization 的方式,保留与滑窗滑出去的状态量相关的约束。让我们来看看在 VINS-Mono 的代码中,对于 Marginalization 是怎么操作的。
Marginalization 基础
简单回顾一下 Marginalization 的基本原理。这部分内容参考了贺博、Lemonade_和 Hansry 的博客。[1][2][3]
在 GN 或者 LM 求解非线性优化问题的时候,本质上就是求解: $ H \delta x = b $
其中 $ H = J^T J, b = J^Te$,$J$ 表示对应状态量下的雅可比矩阵,$e$ 表示对应状态量下的残差项。
可以人为地将 $\delta x$ 分为 $\delta x_1$ 和 $\delta x_2$两部分,因此有
$$ \begin{bmatrix}
H_{11} & H_{12} \\
H_{21} & H_{22}
\end{bmatrix} \begin{bmatrix}
\delta x_1 \\
\delta x_2
\end{bmatrix} = \begin{bmatrix}
b_1 \\
b_2
\end{bmatrix} $$
假设要丢弃 $x_2$,通过高斯消元的方式,可以得到 $ (H_{11} - H_{12}H_{22}^{-1}H_{21})\delta x_1 = b_1 - H_{12}H_{22}^{-1}b_2 $
通过这种方式,即使不求解 $x_2$,也可以得到 $x_1$的解。这个过程在数学上被成为舒尔补。
对应到SLAM问题中,如下图中表示的因子图,我们想要边缘化滑窗内最前面的关键帧 $X_{p1}$。则 $X_{p1}$ 即为上述式子中的 $x_2$,其他关键帧和地图点为 $x_1$
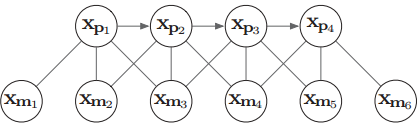
因此我们利用舒尔补可以将上图变换为下图。

神奇的事情就这么发生了,$X_{p1}$就这样消失了,但是对于剩余状态量的求解没有发生任何信息上的损失。
其对应的信息矩阵$H = (H_{11} - H_{12}H_{22}^{-1}H_{21}) = J^TJ$
其对应的$b = b_1 - H_{12}H_{22}^{-1}b_2 = J^Te$,则对应的残差为 $e = (J^T)^{-1} b$
这部分即可认为是边缘化$X_{p1}$时,对剩余状态量留下的残差项以及对应的雅可比矩阵。即使后续滑窗中补入了新的关键帧以及地图点,这部分残差依旧会在非线性优化过程中被考虑。
不过还遗留一个非常关键的问题,由于剩余状态量还在滑窗内会被继续优化,当引入新的观测后,这些状态量是会发生变化的,此时就和边缘化$X_{p1}$时的状态量不一样了,从而导致雅可比和残差项都发生了变化。
这下完犊子了,$X_{p1}$已经被丢掉了,已经不可能再把$X_{p1}$拿回来重新再计算了。因此,这里就第一次引入了 First Estimate Jocabian(FEJ)的概念。既然没法重新算雅可比,那干脆直接就固定雅可比,然后用这个固定的雅可比利用一阶泰勒展开去估计新的残差$e^{*}$。即 $e^{*} = e + J dx$
至此有了关于边缘化的雅可比和会不断更新的残差,边缘化的信息就会在后续的非线性优化过程中被保留。
VINS-Mono中 的 Marginalization
弄明白了 Marginalization 的理论基础,再来看 VINS-Mono 中的相关代码,就非常的丝般顺滑了。我们先看要边缘化滑窗中最前面一个关键帧,VINS-Mono是怎么实现的。
先明确几个关键的变量,直接看注释。
首先,是要把所有观测,包括视觉观测项,IMU观测项以及上一次的边缘化信息都添加进来。通过这些信息可以计算当前状态量下的雅可比和残差。
|
|
之后是调用 preMarginalize 函数得到各个观测的雅可比和残差,顺带把优化变量的值给拷贝出来
|
|
最后是通过调用 marginalize 函数得到本次边缘化的结果,即边缘化的雅可比矩阵和残差
最后来看看怎么利用边缘化得到的雅可比和残差,构造先验信息进入到非线性优化的。即对应的 MarginalizationFactor::Evaluate 函数
|
|
最后的最后,不要忘记,由于滑窗是会改变优化变量的地址的,因此对被保留的优化变量的地址进行更新。
至此,VINS-Mono的边缘化滑窗中最前面的关键帧的流程就走完了。
而边缘化滑窗中最新的非关键帧,就不再展开叙述了,基本上是大同小异的。
再谈 FEJ
之前在Marginalization 基础章节中提到,由于我们已经把边缘化的优化变量丢弃了,因此当被保留的优化变量发生变化时,是无法对雅可比进行更新。因此针对这种情况,固定雅可比更像是一种无奈之举。
而其实不仅仅针对边缘化的雅可比,其实针对整个优化问题来说,也会存在求解雅可比时,线性展开的位置不一致。
再来看下图。假设这个时候我们引入了新的视觉观测 $X_{m7}$,而且 $X_{m7}$ 与 $X_{p4}$ 产生了约束。因此对于 $X_{p4}$,边缘化的残差对于$X_{p4}$的雅可比从边缘化发生时就已经固定不变了,而 $X_{m7}$ 对于 $X_{p4}$ 的雅可比却可以随着优化的迭代过程中不断被更新,这就导致了对于 $X_{p4}$ 来说,在同一个优化问题里,在两个不同的位置被线性展开,这可能会导致其信息矩阵的零空间发生变化,从而在求解时引入错误信息。因此,为了保证一致性,对于有边缘化信息的非线性优化问题,所有的优化变量的雅可比都应该使用优化迭代开始前的雅可比,在优化迭代的过程中不发生变化。这就是真正意义上的 FEJ!
然而….,VINS-Mono并没有这么做,因为据作者说,在VINS-Mono中使用FEJ的实际效果不如不使用FEJ…
卒…
参考文献
[1] SLAM中的marginalization 和 Schur complement
[2] VINS-MONO边缘化策略
[3] VSLAM之边缘化 Marginalization 和 FEJ (First Estimated Jocobian)
[4] VINS-Mono关键知识点总结——边缘化marginalization理论和代码详解
[5] VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator
[6] Decoupled, consistent node removal and edge sparsification for graph-based SLAM
[7] Sliding window filter with application to planetary landing